延迟与带宽入门
网络基础,第一章
速度即功能
过去几年,Web 性能优化(WPO)行业的迅速崛起与快速增长,明确昭示了用户对速度和更快体验的日益重视与迫切需求。这并非仅仅是我们这个不断加速的互联世界中对速度的心理渴求,而是由实证结果驱动的硬性要求——这些结果直接关联着众多在线业务的底线表现:
- 更快的网站带来更好的用户参与度。
- 更快的网站带来更高的用户留存率。
- 更快的网站带来更高的转化率。
简言之,速度即功能。要交付速度,我们需要理解诸多影响因素和根本性限制。本章将聚焦于决定所有网络流量性能的两大关键要素:延迟与带宽(图 1-1)。
延迟
从源端发送数据包到目的端接收所需的时间
带宽
逻辑或物理通信路径的最大吞吐量

图 1-1. 延迟与带宽
深入理解带宽与延迟的协同运作机制后,我们将具备必要的工具,去深入探究 TCP、UDP 及其上层所有应用协议的内部机制与性能特征。
以 Hibernia Express 降低跨大西洋延迟 对于金融市场中的众多高频交易算法而言,延迟是一项关键指标,几毫秒的微小优势可能意味着数百万美元的盈亏。
2015 年 9 月,Hibernia Networks 启用了一条全新的光纤链路(“Hibernia Express”),专门设计用于通过遵循两城之间的大圆航线,确保纽约与伦敦之间的最低延迟。该项目总成本估计超过 3 亿美元,新线路在两城之间实现了 58.95 毫秒的延迟,相比所有其他现有跨大西洋链路拥有约 5 毫秒的优势。这意味着每节省一毫秒就价值超过 6000 万美元!
延迟代价高昂——字面意义上和比喻意义上皆然。
延迟的诸多构成要素
延迟是指消息或数据包从起点传输到终点所需的时间。这是一个简洁而实用的定义,但往往掩盖了大量有用信息——每个系统都包含多个来源或组件,共同构成消息传递的总耗时,理解这些组件及其性能决定因素至关重要。
让我们仔细审视互联网上一个典型路由器的常见贡献组件,该路由器负责在客户端与服务器之间中继消息:
传播延迟
消息从发送方传输到接收方所需的时间,是距离与信号传播速度的函数。
传输延迟
将数据包所有比特推入链路所需的时间,是数据包长度与链路数据速率的函数。
处理延迟
处理数据包头、检查比特级错误并确定数据包目的地所需的时间。
排队延迟
数据包在队列中等待处理的时间。
客户端与服务器之间的总延迟即上述所有延迟之和。传播时间由距离和信号传输介质决定——正如我们将看到的,传播速度通常在光速的一个较小常数因子范围内。另一方面,传输延迟由传输链路的可用数据速率决定,与客户端和服务器之间的距离无关。例如,假设我们要通过两条链路传输一个 10 Mb 的文件:1 Mbps 和 100 Mbps。在 1 Mbps 链路上将整个文件”送上线路”需要 10 秒,而在 100 Mbps 链路上仅需 0.1 秒。
网络数据速率通常以每秒比特(bps)计量,而非网络设备的数据速率通常以每秒字节(Bps)显示。这是常见的混淆来源,务必仔细注意单位。
例如,要通过 1 Mbps 链路将一个 10 兆字节(MB)的文件”送上线路”,我们需要 80 秒。10 MB 等于 80 Mb,因为每字节有 8 比特!
接下来,一旦数据包到达路由器,路由器必须检查数据包头以确定外出路由,并可能对数据运行其他检查——这也需要时间。如今大部分此类逻辑通常在硬件中完成,因此延迟非常小,但它们确实存在。最后,如果数据包到达速率超过路由器的处理能力,则数据包将在输入缓冲区中排队。数据在缓冲区中排队的时间, unsurprisingly,被称为排队延迟。
每个通过网络传输的数据包都会多次经历上述每种延迟。源端与目的端距离越远,传播所需时间越长。沿途遇到的中间路由器越多,每个数据包的处理和传输延迟就越高。最后,路径上的流量负载越高,我们的数据包在一个或多个缓冲区中排队延迟的可能性就越大。 § 本地路由器中的缓冲膨胀
缓冲膨胀(Bufferbloat)是 Jim Gettys 于 2010 年提出并推广的一个术语,是排队延迟影响网络整体性能的典型例证。
其根本问题在于,许多路由器现在配备了大容量输入缓冲区,基于应不惜一切代价避免丢包的假设。然而,这破坏了 TCP 的拥塞避免机制(我们将在下一章讨论),并向网络引入了高且可变的延迟。
好消息是,新的 CoDel 主动队列管理算法已被提出以解决此问题,现已在 Linux 3.5+ 内核中实现。欲了解更多,请参阅 ACM Queue 中的《控制队列延迟》。
光速与传播延迟
正如爱因斯坦在狭义相对论中所阐述的,光速是能量、物质和信息传播的最大速度。这一观测为任何网络数据包的传播时间设定了硬性限制和制约因素。
好消息是光速很高:每秒 299,792,458 米,或每秒 186,282 英里。然而,总是有个”然而”,这是真空中的光速。而我们的数据包通过铜线或光纤等介质传输,这会减慢信号速度(表 1-1)。光速与数据包在材料中传播速度的比值被称为该材料的折射率。数值越大,光在该介质中传播越慢。
光纤的典型折射率值(我们的数据包大多通过它进行长途传输)在 1.4 到 1.6 之间变化——我们在材料质量改进方面正稳步前进,能够降低折射率。但为简化起见,经验法则是假设光纤中的光速约为每秒 200,000,000 米,对应折射率约为 1.5。值得注意的是,我们已经达到了最大速度的一个较小常数因子范围内!这本身就是一项惊人的工程成就。
| 路由 | 距离 | 真空中光传播时间 | 光纤中光传播时间 | 光纤往返时间(RTT) |
|---|---|---|---|---|
| 纽约至旧金山 | 4,148 公里 | 14 毫秒 | 21 毫秒 | 42 毫秒 |
| 纽约至伦敦 | 5,585 公里 | 19 毫秒 | 28 毫秒 | 56 毫秒 |
| 纽约至悉尼 | 15,993 公里 | 53 毫秒 | 80 毫秒 | 160 毫秒 |
| 赤道周长 | 40,075 公里 | 133.7 毫秒 | 200 毫秒 | 200 毫秒 |
表 1-1. 真空与光纤中的信号延迟
光速虽快,但从纽约到悉尼的往返(RTT)仍需 160 毫秒。事实上,表 1-1 中的数字也过于乐观,因为它们假设数据包通过光纤电缆沿大圆路径(地球表面两点间的最短距离)传输。实际上,这种情况很少见,数据包在纽约和悉尼之间会采用长得多的路由。该路由上的每一跳都会引入额外的路由、处理、排队和传输延迟。因此,通过现有网络,纽约与悉尼之间的实际 RTT 在 200-300 毫秒范围内。综合考虑,这仍然看起来相当快,对吧?
我们不习惯以毫秒衡量日常体验,但研究表明,一旦系统中引入超过 100-200 毫秒的延迟,我们大多数人都会可靠地报告感知到明显的”滞后”。一旦超过 300 毫秒延迟阈值,交互常被报告为”迟钝”,而在 1000 毫秒(1 秒)障碍处,许多用户在等待响应时已经进行了心理上下文切换——参见《速度、性能与人类感知》。
要点很简单:要提供最佳体验并保持用户专注于手头任务,我们需要应用在数百毫秒内响应。这留给我们——尤其是网络——的容错空间不大。要取得成功,必须仔细管理网络延迟,并在开发的所有阶段将其作为明确的设计标准。
内容分发网络(CDN)服务提供诸多益处,但其中最主要的是这样一个简单观察:将内容分发到全球各地,并从靠近客户端的位置提供内容,使我们能够显著减少所有数据包的传播时间。
我们可能无法让数据包传播得更快,但我们可以通过战略性地将服务器部署在更靠近用户的位置来缩短距离!利用 CDN 提供数据可以带来显著的性能优势。 §
最后一英里延迟
具有讽刺意味的是,通常不是跨越大洋或大陆,而是最后几英里引入了显著延迟:臭名昭著的最后一英里问题。要将您的家庭或办公室连接到互联网,本地 ISP 需要在整个社区布线、聚合信号,并将其转发到本地路由节点。实际上,根据连接类型、路由方法和部署技术,仅这最初几跳就可能耗费数十毫秒。
根据美国联邦通信委员会(FCC)年度”测量宽带美国”报告,美国境内基于地面的宽带(DSL、电缆、光纤)的最后一英里延迟随时间保持相对稳定:光纤表现最佳(10-20 毫秒),其次是电缆(15-40 毫秒),DSL(30-65 毫秒)。
实际上,这意味着仅到达 ISP 核心网络中最近的测量节点就有 10-65 毫秒的延迟,然后数据包才被路由到目的地!FCC 报告聚焦于美国,但最后一英里延迟是所有互联网服务提供商面临的挑战,无论地理位置如何。对于好奇者,简单的 traceroute 通常可以告诉您关于互联网提供商拓扑和性能的大量信息。
$> traceroute google.com
traceroute to google.com (74.125.224.102), 64 hops max, 52 byte packets
1 10.1.10.1 (10.1.10.1) 7.120 ms 8.925 ms 1.199 ms
2 96.157.100.1 (96.157.100.1) 20.894 ms 32.138 ms 28.928 ms
3 x.santaclara.xxxx.com (68.85.191.29) 9.953 ms 11.359 ms 9.686 ms
4 x.oakland.xxx.com (68.86.143.98) 24.013 ms 21.423 ms 19.594 ms
5 68.86.91.205 (68.86.91.205) 16.578 ms 71.938 ms 36.496 ms
6 x.sanjose.ca.xxx.com (68.86.85.78) 17.135 ms 17.978 ms 22.870 ms
7 x.529bryant.xxx.com (68.86.87.142) 25.568 ms 22.865 ms 23.392 ms
8 66.208.228.226 (66.208.228.226) 40.582 ms 16.058 ms 15.629 ms
9 72.14.232.136 (72.14.232.136) 20.149 ms 20.210 ms 18.020 ms
10 64.233.174.109 (64.233.174.109) 63.946 ms 18.995 ms 18.150 ms
11 x.1e100.net (74.125.224.102) 18.467 ms 17.839 ms 17.958 ms- 第 1 跳:本地无线路由器
- 第 11 跳:Google 服务器
在前面的例子中,数据包从森尼韦尔市出发,跳转到圣克拉拉,然后到奥克兰,返回圣何塞,被路由到”529 Bryant”数据中心,此时它被路由向 Google 并在第 11 跳到达目的地。整个过程平均耗时 18 毫秒。综合考虑还不错,但在同样的时间内,数据包本可以穿越美国大陆的大部分地区!
由于部署技术、网络拓扑甚至一天中的时间不同,不同 ISP 的最后一英里延迟可能差异巨大。作为终端用户,如果您希望提高网页浏览速度,请务必测量并比较您所在地区各种提供商的最后一英里延迟。
对于大多数网站而言,延迟而非带宽才是性能瓶颈!要理解原因,我们需要了解 TCP 和 HTTP 协议的机制——这些主题将在后续章节中介绍。然而,如果您好奇,可以直接跳到《更多带宽并不重要(太多)》。
使用 Traceroute 测量延迟
Traceroute 是一个简单的网络诊断工具,用于识别数据包的路由路径和 IP 网络中每个网络跳的延迟。为识别单个跳,它向目的地发送一系列具有递增”跳数限制”(1、2、3 等)的数据包。当达到跳数限制时,中介返回 ICMP 超时消息,使工具能够测量每个网络跳的延迟。
在 Unix 平台上,该工具可通过命令行 traceroute 运行,在 Windows 上则称为 tracert。
核心网络带宽
光纤充当简单的”光导管”,比人类头发稍粗,设计用于在电缆两端之间传输光。金属线也被使用,但面临更高的信号损失、电磁干扰和更高的终身维护成本。很可能您的数据包将通过两种类型的电缆传输,但对于任何长途传输,它们将通过光纤链路传输。
光纤在带宽方面具有明显优势,因为每根光纤可以通过波分复用(WDM)技术传输多种不同波长(信道)的光。因此,光纤链路的总带宽是每信道数据速率与复用信道数量的乘积。
截至 2024 年,研究人员已经能够复用超过 1000 个波长,每信道峰值容量达到 800 Gbit/s 甚至更高,这意味着单根光纤链路的总带宽超过 800 Tbit/s!我们需要数千根铜线(电气)链路才能匹配这一吞吐量。毫不奇怪,现在大多数长途传输,如洲际之间的海底数据传输,都通过光纤链路完成。每根电缆携带多股光纤(四股是常见数量),这意味着每根电缆的带宽容量达到数百 Tbit/s。
网络边缘带宽
构成互联网核心数据路径的骨干网或光纤链路能够以每秒数百 Tbit 的速度传输数据。然而,网络边缘的可用容量要少得多,且因部署技术而异:拨号、DSL、电缆、各种无线技术、光纤到户,甚至本地路由器的性能。用户的可用带宽是客户端与目的服务器之间最低容量链路的函数(图 1-1)。
Akamai Technologies 运营着全球 CDN,服务器遍布全球,并在其网站上免费提供关于其服务器观测到的平均宽带速度的季度报告。表 1-2 捕捉了截至 2024 年初的宏观趋势。
| 排名 | 国家/地区 | 平均 Mbps | 同比增长 |
|---|---|---|---|
| - | 全球 | 约 50-100 | 持续提升 |
| 1 | 新加坡 | 300+ | 稳定增长 |
| 2 | 智利 | 250+ | 快速增长 |
| 3 | 泰国 | 250+ | 快速增长 |
| 4 | 丹麦 | 200+ | 稳定增长 |
| 5 | 中国(香港) | 200+ | 稳定增长 |
| … | |||
| ~10 | 美国 | 200+ | 稳定增长 |
表 1-2. 2024 年初 Akamai 服务器观测到的平均带宽速度
上述数据排除了移动运营商的流量,这是一个我们稍后将详细审视的主题。目前, suffice it to say 移动速度高度可变且通常较慢。然而,即使考虑到这一点,2024 年初全球平均宽带带宽已达到约 50-100 Mbps,领先国家超过 300 Mbps。美国也进入了 200+ Mbps 的行列。
作为参考,流媒体播放高清视频根据分辨率和编解码器可能需要 5 到 25 Mbps。因此,美国普通用户可以在网络边缘流畅播放高分辨率视频,但这也会消耗其大部分链路容量——对于多用户家庭而言,这不是一个乐观的前景。
确定任何给定用户的带宽瓶颈所在通常是一项重要但非 trivial 的练习。再次,对于好奇者,有许多在线服务,如 Ookla 运营的 speedtest.net(图 1-2),提供针对附近服务器的上行和下行测试——我们将在 TCP 讨论中看到为什么选择本地服务器很重要。在这些服务之一上运行测试是检查您的连接是否达到本地 ISP 宣传速度的好方法。
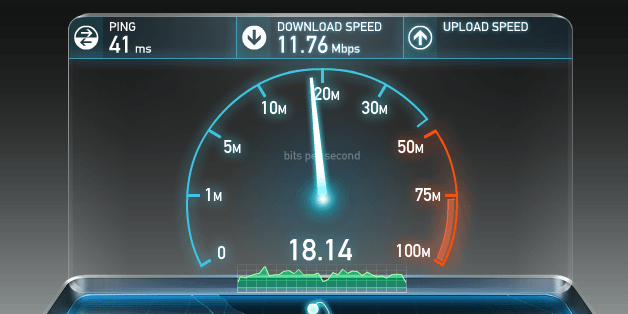
图 1-2. 上行和下行测试(speedtest.net)
然而,虽然与 ISP 的高带宽链路是理想的,但它也不能保证端到端性能;仅仅因为带宽测试承诺高数据速率,并不意味着您可以或应该期望从其他远程服务器获得相同性能。网络可能因高需求、硬件故障、集中式网络攻击或众多其他原因在任何中间节点拥塞。吞吐量和延迟性能的高度可变性是我们数据网络的固有特性——预测、管理和适应不断变化的”网络天气”是一项复杂任务。 §
实现更高带宽与更低延迟
我们对更高带宽的需求正在快速增长,很大程度上是由于流视频的日益普及,现在它负责远超过一半的所有互联网流量。好消息是,虽然可能不便宜,但有多种策略可供我们增加可用容量:我们可以在光纤链路中增加更多光纤,在拥塞路由上部署更多链路,或改进 WDM 技术以通过现有链路传输更多数据。
电信市场研究和咨询公司 TeleGeography 估计,截至 2024 年,我们平均仅使用了已部署海底光纤链路可用容量的约 30-40%。更重要的是,近年来新增的跨太平洋电缆容量大部分归因于 WDM 升级:相同的光纤链路,两端更好的技术来复用数据。当然,我们不能期望这些进步无限期持续,因为每种介质都会达到收益递减点。尽管如此,只要企业经济允许,带宽吞吐量没有理由不能随时间增加——如果所有其他方法都失败,我们可以增加更多光纤链路。
另一方面,改善延迟则是一个完全不同的故事。光纤链路的质量可以改进,使我们更接近光速:折射率更低的更好材料和沿途更快的路由器。然而,鉴于我们当前的速度已经达到光速的约 2/3,这种策略最多只能带来约 30% 的适度改进。不幸的是,物理定律根本无法绕过:光速为最小延迟设定了硬性限制。
或者,既然我们无法让光传播得更快,我们可以缩短距离——地球上任意两点之间的最短距离由它们之间的大圆路径定义。然而,由于物理地形、社会和政治原因以及相应成本的限制,铺设新电缆也并不总是可行。
因此,要提高我们应用的性能,我们需要在架构和优化协议及网络代码时,明确意识到可用带宽的限制和光速的限制:我们需要减少往返次数,将数据移近客户端,并构建能够通过缓存、预取和各种类似技术隐藏延迟的应用,如后续章节所述。